OpenAI gave me access to DALL-E 2 and here is my opinion.
OpenAI gave me access to DALL-E 2 and here is my opinion.

So, I requested OpenAI for an access to test out its amazing image generation AI called DALL-E 2. Honestly I was inspired by DALL-E when it first came out and thats why I wrote one of my most famous article which was called: Making an AI to make beautiful Art using GPT-3, CLIP and the CC12M Dataset DALL-E was the AI that Inspired me to make this AI.
Lets first find out how DALL-2 Works:
CLIP
One of the key components of the DALL-E 2 architecture is CLIP. CLIP is important to DALL-E 2 because it allows text and images to communicate with each other. This means that language can be used to teach computers how different images are related to each other. This fluency prescribes a simple way to carry out this teaching.
To best understand CLIP, it is helpful to see how it improves upon the shortcomings of previous computer vision systems. This means that until CLIP, neural methods for computer vision involved taking a large dataset of images and then hand labeling them into a set of categories. Even though today’s models are really good at this task, there is still a limit to how well they can do because they need to have categories that are already selected. For example, if you took a picture of a street and asked a system to describe it, it could tell you how many cars and signs there were, but it wouldn’t be able to give you a feel for the scene as a whole. If there aren’t enough images to produce a category, the model won’t classify it.
CLIP’s success comes from its ability to train models to not just identify an image’s category from a pre-defined list, but to also identify the caption of the image from a list of random captions. This allows the model to use language to more precisely understand the difference between two things, rather than having a human labeler dictate in advance whether or not these belong in the same category. CLIP is able to create a vector space representing both features of images and features of language by completing the ‘pre-training task’ described above. The shared vector space effectively provides models with a dictionary that translates images and text, allowing for at least a semantical understanding between the two.
CLIP is able to create a vector space representing both image and language features, allowing for training on both inputs. This shared vector space allows models to effectively translate between images and text, providing a sort of image-text dictionary. This allows for at least a semantic understanding between the two.0’s capabilities DALL-E 2.0 is capable of much more than just sharing an understanding with others. In order to speak Spanish fluently, one would need to learn not only how to translate English words into their Spanish counterparts, but also how to properly pronounce Spanish words and use correct Spanish grammar. CLIP allows us to see how textual phrases connect to images, providing us with a deeper understanding of the meaning behind the words. We need a way to generate images that accurately represent our understanding of the text. The diffusion model is our second lego building block. It allows us to see how information spreads through a population.
Diffusion Models
Assume you have a Rubik’s Cube that is perfectly solved, with only blocks of a single colour on each side. You now pick a side at random and twist it. Then another side, and another, and another, and so on, until the Rubik’s Cube is considered’scrambled.’ How would you approach the problem? If you forget all of your twists, is there a general way to solve the cube without that information? You could simply take it one step at a time, twisting whatever face brings you closer to having all the same colour on the same side until the problem is solved. More practically, you could train a neural network to go from disorder to less disorder.
This is where diffusion models come into play. You start with an image, randomly scramble its pixels until you have a pure noise image, and then train a model to reduce the noise by changing its pixels step by step until you get back to the original image (or something that resembles it). This results in a model that can generate information — an image — from randomness! We can even get new images by showing the model new, random samples to start from.
We ‘condition’ the diffusion model on the CLIP embeddings to infuse these creations with the semantic meaning of our input text. This simply means that we feed the vectors from our previously described joint CLIP space into the diffusion model, which calculates which pixels to change at each’step’ of the generation process. This enables the model to base its changes on that data.
The technical details of the math and implementation are, of course, more complicated than I have presented here. DALL-E 2 is, at its core is the optimization and refinement of these two technologies.
Visit there official website for more details:
Now that you know how DALL-E 2 works lets see some of its amazing outputs:
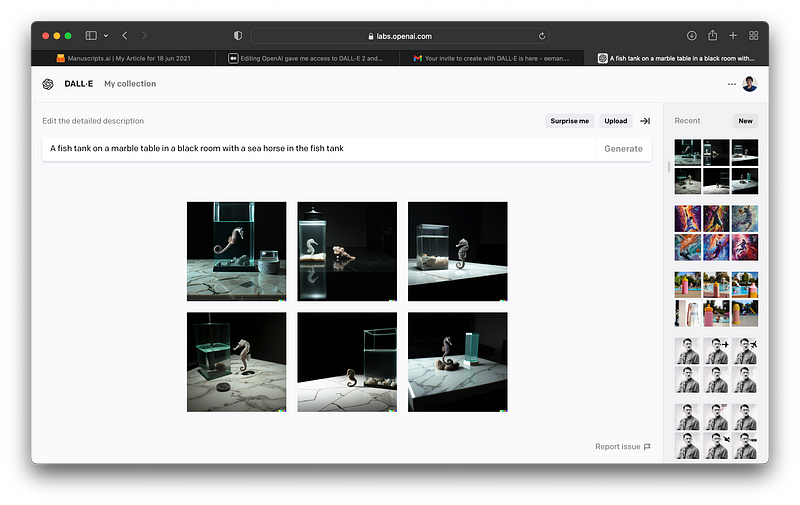





The results are absolutely mind numbing like how are they an AI generated image they are so photo-real ahhh this is why I love AI.
Lets see some more results:
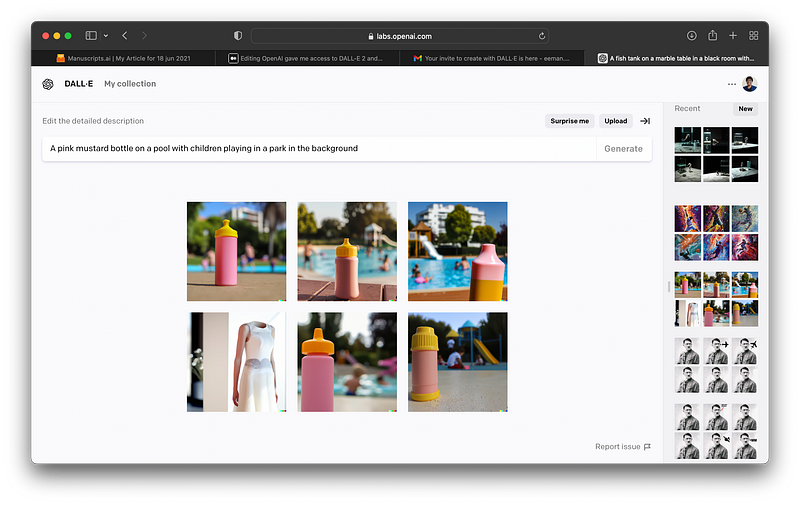





Honestly no wonder they won the Turing test. These generations are absolutely flawless.
So, here is my final review on DALL-E 2. It reminded me why I love AI so much like this is basically giving your imagination to someone to make it into a reality. There is literally infinite possibilities with this thing. Honestly hats off the OpenAI and keep up the good work.
For more of my works check out my Github:
For my day to day AIML updates follow me on twitter:
Thanks for reading 😁, See ya guys next week 👋🏼.