Making a Deep Learning Chandler Bing AI (from f.r.i.e.n.d.s)Part-1
Making a Deep Learning Chandler Bing AI (from f.r.i.e.n.d.s)Part-1

I am a f.r.i.e.n.d.s fan. Chandler and Joey are my favourite characters. Chandler can be super sarcastic but also comforting at the same time. Joey has unlimited energy and has fun. Honestly once I finished the series. It genuinely felt like I missed the characters alot. So, I have gotten the thought before “what if I make a Chandler bing chatbot” but at that time nether did I have the time nor did I have the knowledge to make it.So, now that I have both time and knowledge I thought let's make this and here we are.
So for making this we need to do a lot of stuff:
- Make a dataset containing all the dialogues of friends.
- Make a NLP model.
- Train the NLP model on the dataset.
- Optimise the NLP model.
- Make the AI should be more presentable to public
Lets get started with making the dataset:
To make the dataset we need all the dialogues of friends and whats the best way to get everything said in a series? Yeap it's the subtitles.
So, I downloaded subtitles of all the episodes of friends yes all 229 of them
and as I didn't find a tool for merging all the contents together I had to copy paste them by hand 🙂 It took a ridicules amount of time.
Then came the process of cleaning the subtitle file and keeping only the dialogues and not the time stamps as .sub and .srt files have timestamps on when to display the text on the video.
I used this tool for that.
After the cleaning is done this file is obtained:
Now lets pass it though the following code to make it into a dataframe and covert to csv:
Building the dataset is complete:
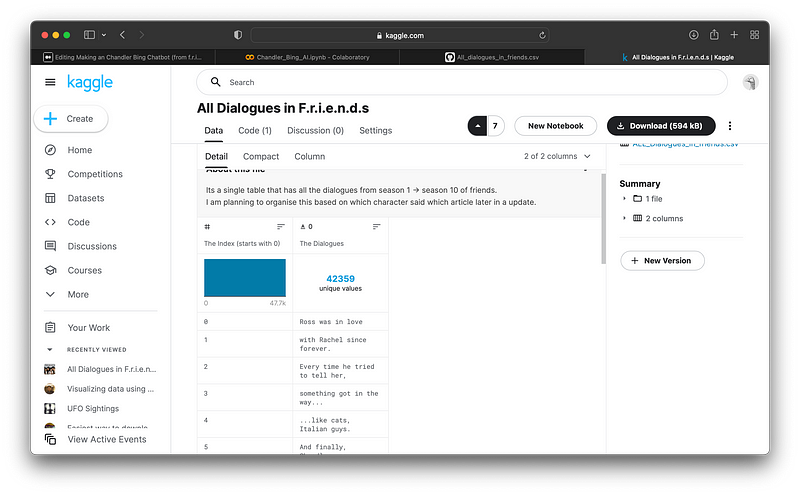
If you clicked this you know what friends is. So, here is its every dialoguewww.kaggle.com
The dataset has more than 42,000 values
So I wanted to make the dataset more detailed so lets add sentiment analysis to the data so that we can differentiate +ve and -ve dialogues.
I will use Textblob for the sentiment analysis.
Lets get started with the code of this:
so after that the output will look something like this:
If you clicked this you know what friends is. So, here is its every dialoguewww.kaggle.com
The data is too big to display via Github Gist.
So, I wasn't satisfied with the sentiment analysis of TextBlob so I made another analysis dataset using nltk.
Lets first get the downloads:
now lets get the Dialogues and preprocess them and find the positive count, negative count and the sentiment:
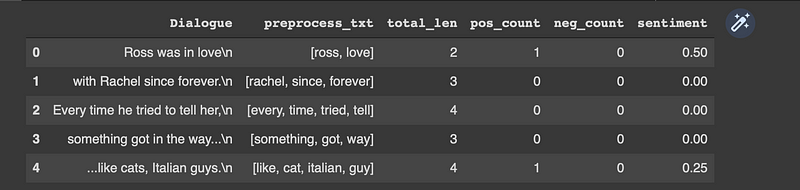
Now we have the dataset to train our NLP(Natural Language Processing) model from.
In the next part of this article I will make a NLP model from scratch and train it so stay tuned.
If you liked this article a follow in medium helps me out alot.
The Dataset:
If you clicked this you know what friends is. So, here is its every dialoguewww.kaggle.com
The Colab Notebook:
For more stuff check our my GitHub:
For my day to day AIML research updates follow me on twitter:
Thanks for reading😁, See ya guys next week 👋🏼