How to make an advanced intelligent chatbot using tensorflow.
How to make an advanced intelligent chatbot using tensorflow.
Firstly lets get started with the imports:-
import tensorflow as tf
import numpy as np
import pandas as pd
import json
import nltk
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.layers import Input, Embedding, LSTM , Dense,GlobalMaxPooling1D,Flatten
from tensorflow.keras.models import Model
import matplotlib.pyplot as plt
Now lets import the datasets:-
#importing the dataset
with open('content.json') as content:data1 = json.load(content)
Now lets actually make the ‘content.json’ file which will include our data regarding the possible questions and its answers the AI can be asked:-
Getting the data from ‘intent.json’ and storing them in lists:-
#getting all the data to lists
tags = []
inputs = []
responses={}for intent in data1[‘intents’]:
Using the data and storing it as dataframe using pandas:-
#converting to dataframe
data = pd.DataFrame({“inputs”:inputs,“tags”:tags})data = data.sample(frac=1)
Removing the punctuations from the sentences:-
#removing punctuations
import string
data[‘inputs’] = data[‘inputs’].apply(lambda wrd:[ltrs.lower() for ltrs in wrd if ltrs not in string.punctuation])
data[‘inputs’] = data[‘inputs’].apply(lambda wrd: ‘’.join(wrd))
data
Tokenising the data:-
#tokenize the data
from tensorflow.keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer(num_words=2000)
tokenizer.fit_on_texts(data[‘inputs’])
train = tokenizer.texts_to_sequences(data[‘inputs’])
Applying the padding to the data:-
#apply padding
from tensorflow.keras.preprocessing.sequence import pad_sequences
x_train = pad_sequences(train)
Encoding the data:-
#encoding the outputs
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y_train = le.fit_transform(data[‘tags’])
input_shape = x_train.shape[1]
print(input_shape)
Defining the vocabulary:-
#define vocabulary
vocabulary = len(tokenizer.word_index)
print(“number of unique words : “,vocabulary)
output_length = le.classes_.shape[0]
print(“output length: “,output_length)
Now after all that done lets actually make the model:-
#creating the model
i = Input(shape=(input_shape,))
x = Embedding(vocabulary+1,10)(i)
x = LSTM(10,return_sequences=True)(x)
x = Flatten()(x)
x = Dense(output_length,activation=”softmax”)(x)
model = Model(i,x)
Compiling the model is easy its just a line of code:-
#compiling the model
model.compile(loss=”sparse_categorical_crossentropy”,optimizer=’adam’,metrics=[‘accuracy’])
Now lets train the model and print out the accuracy:-
#training the model
train = model.fit(x_train,y_train,epochs=200)
Now lets form a graph according to our accuracy data:-
#plotting model accuracy
plt.plot(train.history[‘accuracy’],label=’training set accuracy’)
plt.plot(train.history[‘loss’],label=’training set loss’)
plt.legend()
Now for actually using the chatbot lets make a small code.
#chatting
import random
while True:
texts_p = []
prediction_input = input(‘You : ‘)
#removing punctuation and converting to lowercase
prediction_input = [letters.lower() for letters in prediction_input if letters not in string.punctuation]
prediction_input = ‘’.join(prediction_input)
texts_p.append(prediction_input)
#tokenizing and padding
prediction_input = tokenizer.texts_to_sequences(texts_p)
prediction_input = np.array(prediction_input).reshape(-1)
prediction_input = pad_sequences([prediction_input],input_shape)
#getting output from model
output = model.predict(prediction_input)
output = output.argmax()
#finding the right tag and predicting
response_tag = le.inverse_transform([output])[0]
print(“Dew : “,random.choice(responses[response_tag]))
if response_tag == “goodbye”:
break
And now we have finished making our chatbot use to as you want.
Have fun coding. hehe😁
Here are some of the outputs:-
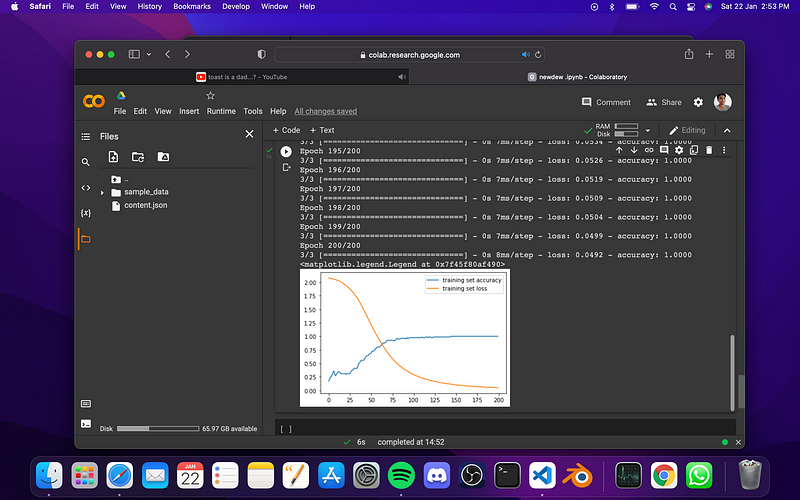
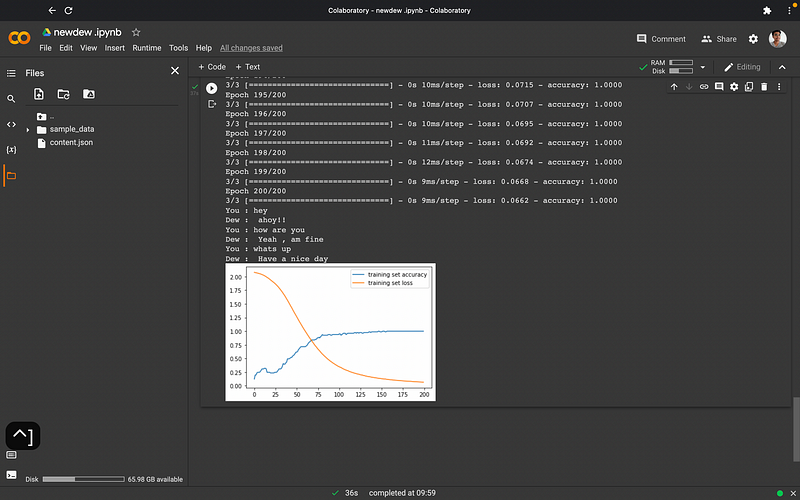
If you liked this article follow me on GitHub: https://github.com/Eeman1113
stars would be appreciated 😁.